
前一篇提到了:從 LLM 輸入問題後,按下 Enter「視野裡」發生什麼事?並以 ChatGPT 為例,實際觀察了 ChatGPT 介面中可能會發生、可以設定的功能。
同時我們發現了作為 LLM 代表之一的 ChatGPT 中,一個聊天各自表述,有很多種聊天的情境都包裹在我們如今熟悉的對話框中,所以今天這一篇想要來提到,最核心的 LLM「聊天本身」是怎麼運作的。
要可以在 LLM 中輸入問題 (prompt) 並得到一個答案,這個背後的 LLM 是怎麼做到的?我們將一段文字丟進 LLM,我們先不管平台方幫我們做的任何加油添醋,就是純聊天的丟入一段文字進入 LLM。
我們透過網頁問出一段問題按下 Enter,發現 ChatGPT 發了一個 /conversation 的 POST request,將我們所打的文字、所選擇的模型等等資訊傳送過去,並同時建立起一個單向的 event stream 通道,持續接收一個個文字生成結果回來並顯示。
e.g. 當我輸入下一段: 我想要寫一篇關於 AI 怎麼運作的系列文章,可以怎麼擬定大綱? 後按下 Enter,接著在這個 request 之下,以一系列的 event,我們的電腦會收到一段段文字的生成結果,像是:
{"v": "1. **AI \u662f\u4ec0\u9ebc\uff1f\u70ba\u4ec0\u9ebc\u73fe\u5728\u9019"}
{"v": "\u9ebc\u91cd\u8981** \n2. **\u5f9e\u8cc7\u6599\u5230\u7b54\u6848\uff1aAI \u7684\u57fa\u672c\u904b\u4f5c\u6d41\u7a0b** \n3. **AI \u5b78\u7fd2"}
將編碼轉換後,就是:
1. **AI 是什麼?為什麼現在這
2. 麼重要** \n2. **從資料到答案:AI 的基本運作流程** \n3. **AI 學習
那送到 Server 後發生什麼事,Server 怎麼一段段的生成出這段文字的?
我們不得而知具體在 Server 中還做了哪些文字處理:也許是頭尾幫我們增減了一些字串,有助於生成更好的文字;或做了文字處理,讓文字變得更單純或避免危險的輸入;或者將必要的文字區塊代入系統需要的參數等等。
但我們最在意的是 Server 裡面的黑盒子,為什麼可以產生文字。在說這個特別厲害的黑盒子之前,作為普通的 Model 為什麼可以知道要生成什麼?
想像我們寫出了一段方程式 f(x) = ax +b,當 a = 1、b = 2,我們就可以說,當 f(3) = 5。同樣的,今天的 Model 只是一個更為複雜的方程式有上億個 a, b, x、以及更難以取得這個方程式的方法。最終透過 f(一段句子) = 最有可能出現的下一個字只是問題在於這個方程式的 x 是什麼、f(x) 是什麼、以及方程式的架構上長什麼樣子。
那相比於 f(x) = ax +b 這種過於簡單的 model,LLM 這種大 model 有什麼不同,為什麼可以產生長篇大論的一段句子?
LLM 之所以可以產生句子,是因為它在進行一段文字接龍,當我們提供一段句子、他就去預測最有可能出現的下一個文字是什麼,並生成出來。接著再將生成的文字接在原本的句子後面,再去預測最有可能的下一個文字又是什麼。
就好比以上面的問題為例,黑盒子的文字接龍過程可能就會如下:
送進 LLM: 我想要寫一篇關於 AI 怎麼運作的系列文章,可以怎麼擬定大綱?
LLM 生成: 1
送進 LLM: 我想要寫一篇關於 AI 怎麼運作的系列文章,可以怎麼擬定大綱?1
LLM 生成: .
送進 LLM: 我想要寫一篇關於 AI 怎麼運作的系列文章,可以怎麼擬定大綱?1.
LLM 生成: *
送進 LLM: 我想要寫一篇關於 AI 怎麼運作的系列文章,可以怎麼擬定大綱?1. *
LLM 生成: *
送進 LLM: 我想要寫一篇關於 AI 怎麼運作的系列文章,可以怎麼擬定大綱?1. **
LLM 生成: A
送進 LLM: 我想要寫一篇關於 AI 怎麼運作的系列文章,可以怎麼擬定大綱?1. **A
LLM 生成: I
送進 LLM: 我想要寫一篇關於 AI 怎麼運作的系列文章,可以怎麼擬定大綱?1. **AI
...持續接龍
這稍微簡化了 Model 的產出答案的可能性,以中文字為例,常用字有 3500 字,如果僅以三個字限制可能答案就有 3500+3500^2+3500^3 = 400 多億種可能性,但只有 3 個字以內的句子能構成對話嗎?今天哪個 LLM 不是動輒讀一本書、給你上百上千的長度不等的長篇大論。一段句子預測另一段長度不等的句子這可能性是多大的天文數字啊?還不如提供一段句子,預測 1/所有文字,比起上述的天文數字可愛得多了。
那知道了其實 LLM 試圖在接收到的是一段句子、回傳的是在這段句子後,哪一個文字最該出現。我們有可能稍微可以知道這個 Model 長什麼樣子嗎?
它是一個無限長的 f(x) = ax + b 嗎?還是他不只一個 f(x) = ax + b 呢?事實上都不是,他更像是一個一直在對數字編碼加工的過程。而為避免在第一階段迷失在數學的汪洋中,以下會高度簡化地介紹,不會在這個階段說到「矩陣」或「向量」這些字眼,也會忽略更近代的實做。就是以最陽春的 Transformer 架構來介紹。
首先,我們提問的句子不會是以句子的方式被丟進這個方程式,因為句子是一大段文字,而且方程式只能讀數字。可是我們怎麼將不是數字的東西轉為數字提供給它?
我們先是透過查一個叫做 Token List 的表,將一段句子拆成一個個基本單位,以中文為例可能就是一個文字、英文可能是 1-3 個單字,完全依據這個表而定。
下圖是 ChatGPT 提供的 Tokenizer 小工具 可以看到,在 GPT-4o 模型,31 個字的問題會被拆解成 26 個 Token。
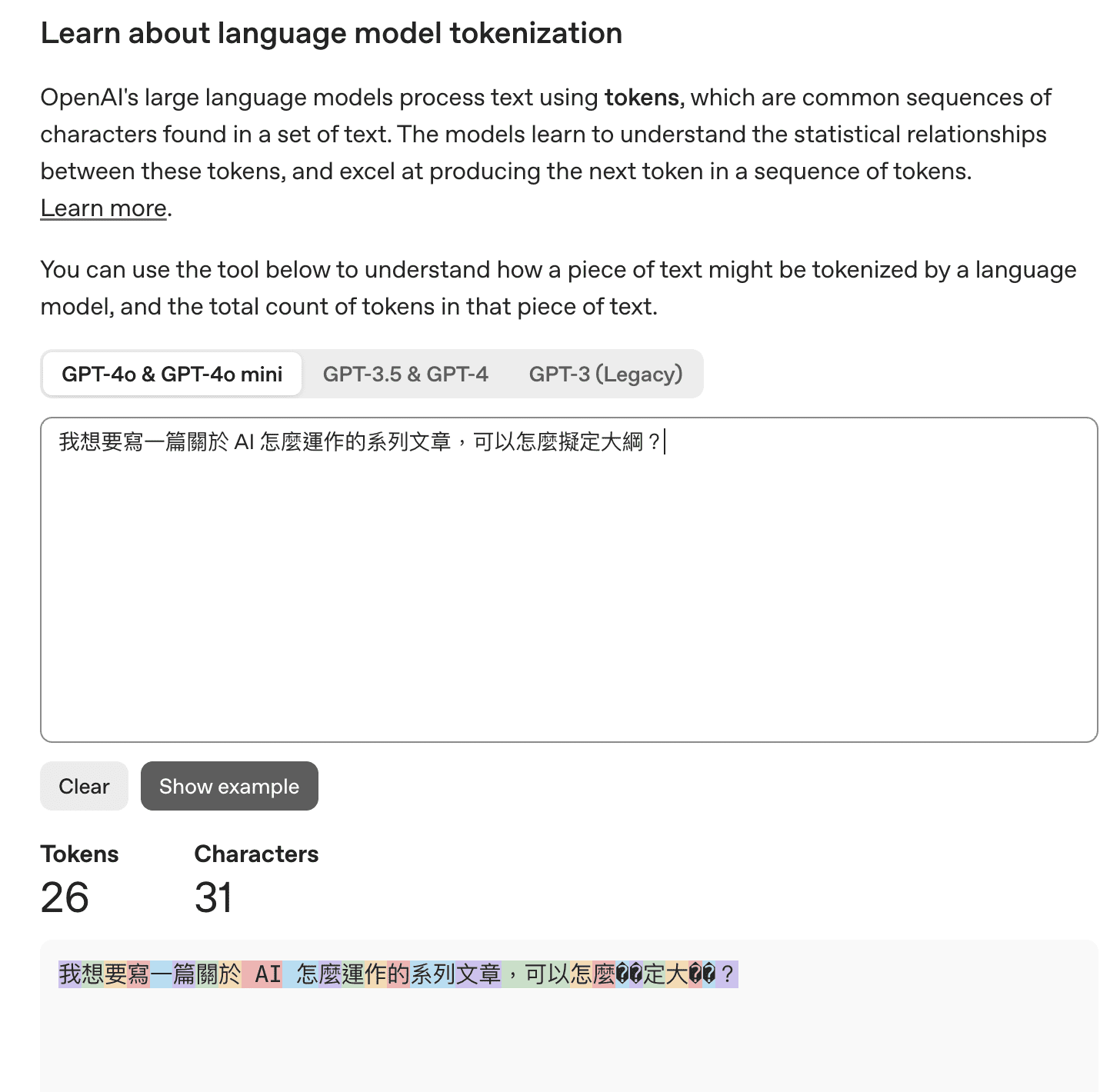
當拆解為一個個獨立的 Token 單位後,再接著將這些單位轉為一組數字,好讓我們的方程式 Model 可以讀懂這些文字。當然這些數字並不會是某種隨機亂數,這些數字是在數學意義上,能讓 Token 之間具備某種關聯性,例如,狼與狗之間的數字關係,比起狼與汽車,會有更接近的數字關係。
於是我們透過 Token Embedding 的表,從中找到對應的 Token 應該是什麼數字編碼,同時模型也會另外加入每個 Token 在句子中的位置資訊在這一串編碼中。這組神秘數字人想必是看不懂的,但 Model 一看就知道:「喔喔!這是某某 Token 且現在 Token 在一個句子中的哪個位置。」
又或許可以比喻為一組該 Token 的生命靈數(X)。
截至為止只解釋了:一段句子有哪些 Token,以及這些 Token 分別代表什麼數字,但還不知道這些 Token 在這樣句子的組合下,代表什麼意思。
舉例來說,以上面有出現的 Token -「寫」來說,「寫」生是繪畫、「寫」作是文字創作,雖然都是「寫」,但實際上語意卻相去甚遠。所以接下來我們要透過一個知名的模組 Attention Module,在數字中增添上述的資訊。
當在「我想要寫一篇關於 AI 怎麼運作的系列文章,可以怎麼擬定大綱?」的句子下,同樣是一個「寫」字,要怎麼此字跟句子有所關聯?
也許可以將關聯拆解成三個問題,當我們經過某種加工器,就可以回答下列問題:
Token 本身的視角 (Query):「寫」這個字,應該要在乎什麼樣的資訊?
Token 以外的視角 (Key):哪些文字會跟這些「寫」要在乎的資訊有關?
Token 綜合起來的視角 (Value):「寫」本身的字意與其他字結合後可能是什麼意思?
當數字組通過加工器 ,我們就可以得到帶有上述三種資訊的結果。同樣地,雖然以下說的是加工器,但實際的行為是更加複雜的數學向量運算,同時也帶有細緻地分布處理方式,這些都在這個階段先忽略。
Token 應該要在乎什麼樣的資訊:我們將「寫」這個 Token 的數字與 Query 加工器計算,就會知道今天遇到「寫」這個字要知道:寫什麼?怎麼寫?誰要寫?等等的資訊。
哪些 Token 會跟要在乎的資訊有關:同時我們將「我」、「想」、「要」、「一」、「篇」等等的其他 Token 的神秘數字也一樣在 Key 加工器計算,就會知道像:「我」能代表誰做什麼!「一」能代表幾個!這樣的資訊。
透過上述兩者的結合,可以知道什麼 Token 能回答上述問題,像「寫」的「誰要寫?」能被「我」能代表的「誰做什麼」給回答。但雖然知道關係,卻不知道融合起來可能是什麼模樣。
透過這個方式,我們就可以將一句話中的所有 Token 建立起彼此之間的數字關係,讓我們知道特定文字在這個句子脈絡下的意義是什麼。
在 Attention 階段,已經將一段句子中的每一個 Token,都加工計算出包含:Token 本身的字意、情境中的關聯數字,並綜合起的一組數字編碼。但我們還需要讓 LLM 的回答是具有常識的,如世界上既有的運作規則,像:AI 怎麼運作的?大綱通常長什麼樣子?等等的基本概念。
這些常識會變成另一個加工器,當一段句子中的每一個 Token 通過時,都會經過計算加工,讓知識訊號被加工進這些 Token 數字編碼之中。好比「我想要寫一篇關於 AI 怎麼運作的系列文章,可以怎麼擬定大綱?」的數字化結果,經過這些加工器,可能會被強化「系列」、「文章」、「大綱」等重點訊號。
最終一段文字被數字化、加工每一個文字在句子情境中的意思、甚至進一步加工關於世界知識的資訊,最後我們要轉回預測下一個文字。
於是我們我們會將這一大組編碼,與一個擁有所有文字的數字編組去對應,看哪一個文字要有最高機率被顯示。
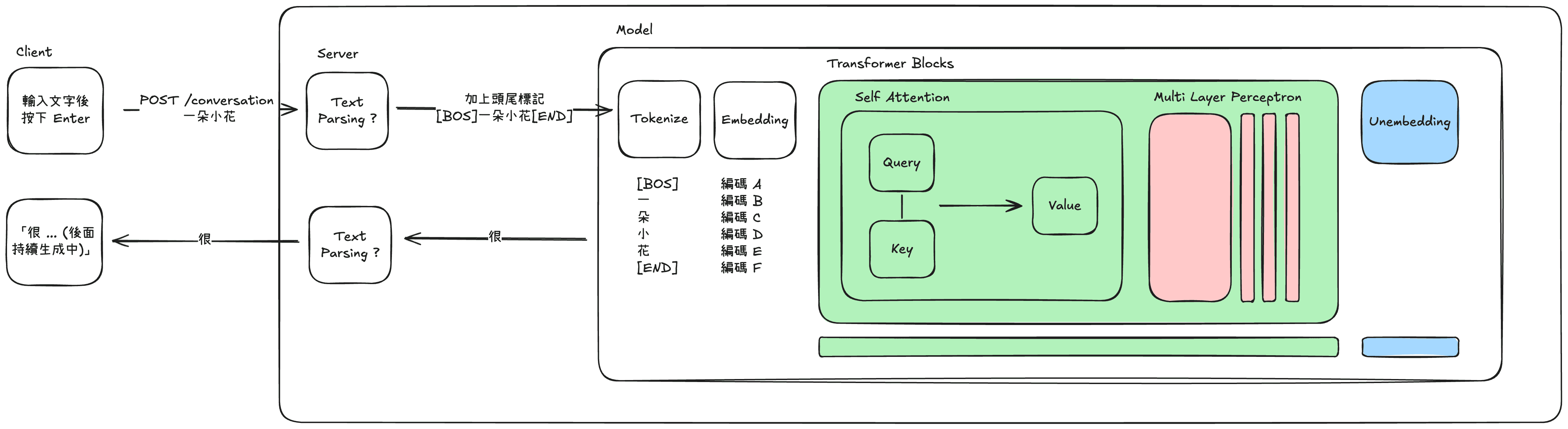
以上以非常非常簡略的方式介紹了 LLM Transformer 架構的運作方式,當一個文字會經過上述架構的層層加工,讓 LLM 能具有常識、情境合理的生成下一個文字。
而在架構中,我們也發現了很多神秘的表格、加工器,這些加工器為什麼可以做到這件事情?因為我們讓機器學習了這些加工器、表格應該要長什麼樣子。
